Automated Detection of Foreground Speech with Wearable Sensing in Everyday Home Environments: A Transfer Learning Approach
ABSTRACT
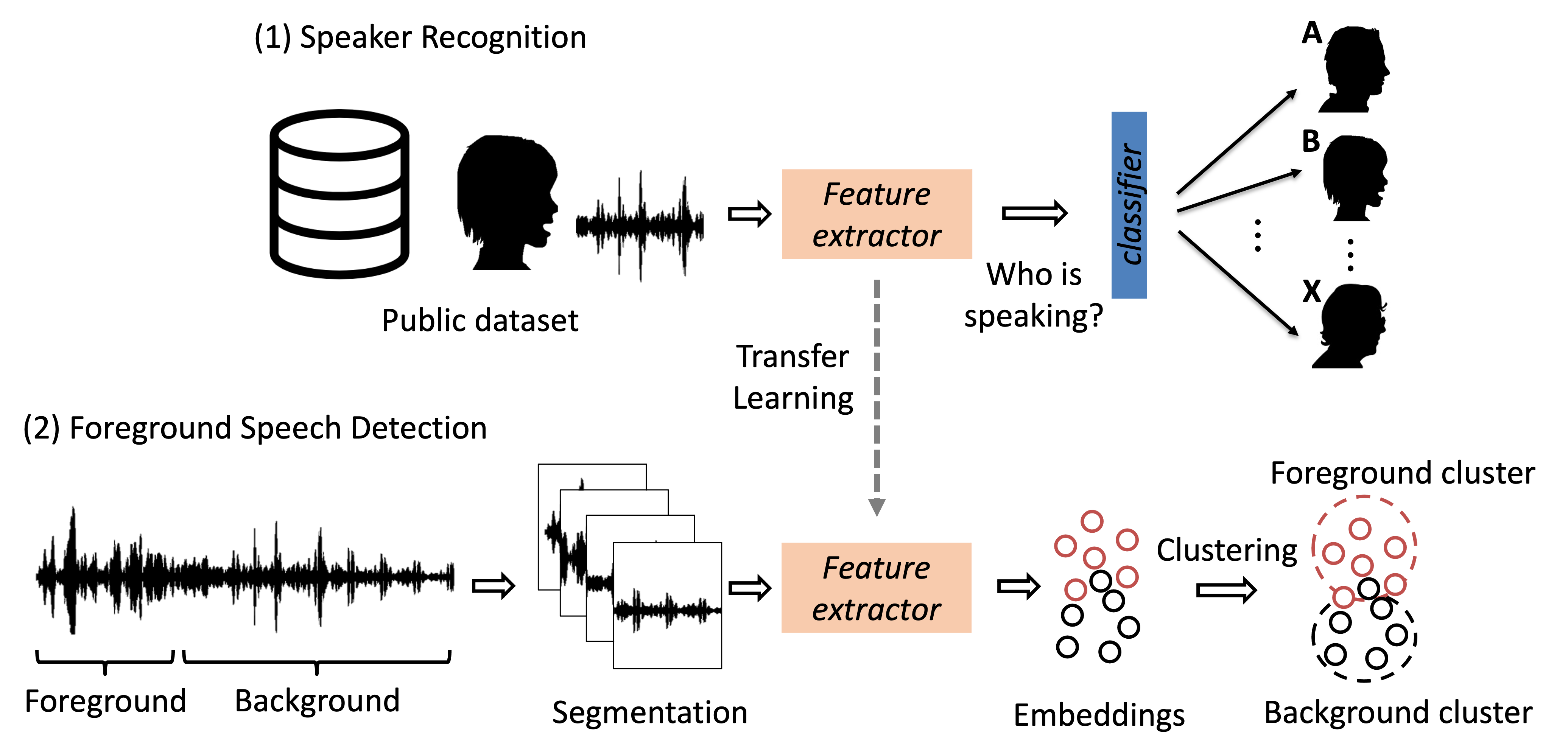
Acoustic sensing has proved effective as a foundation for numerous applications in health and human behavior analysis. In this work, we focus on the problem of detecting in-person social interactions in naturalistic settings from audio captured by a smartwatch. As a first step towards detecting social interactions, it is critical to distinguish the speech of the individual wearing the watch from all other sounds nearby, such as speech from other individuals and ambient sounds. This is very challenging in realistic settings, where interactions take place spontaneously and supervised models cannot be trained apriori to recognize the full complexity of dynamic social environments. In this paper, we introduce a transfer learning-based approach to detect foreground speech of users wearing a smartwatch. A highlight of the method is that it does not depend on the collection of voice samples to build user-specific models. Instead, the approach is based on knowledge transfer from general-purpose speaker representations derived from public datasets. Our experiments demonstrate that our approach performs comparably to a fully supervised model, with 80% F1 score. To evaluate the method, we collected a dataset of 31 hours of smartwatchrecorded audio in 18 homes with a total of 39 participants performing various semi-controlled tasks.
FULL CITATION
Liang, D., Xu, Z., Chen, Y., Adaimi, R., Harwath, D. and Thomaz, E., 2022. Automated detection of foreground speech with wearable sensing in everyday home environments: A transfer learning approach. arXiv preprint arXiv:2203.11294.